Seeking an efficient way to manage large datasets? Look no further than "partition by SQL"!
Partitioning in SQL involves dividing a table into smaller, more manageable sections based on specific criteria. This technique offers numerous advantages, including faster query execution, improved scalability, and optimized storage utilization.
The importance of partitioning lies in its ability to enhance performance, especially for complex queries involving large datasets. By dividing the table into smaller partitions, the database can efficiently locate and retrieve the necessary data, significantly reducing query response times.
Moreover, partitioning facilitates scalability, enabling the database to handle growing data volumes without compromising performance. As new data is added, it can be easily assigned to the appropriate partition, maintaining optimal query execution speeds.
Partition by SQL
Partitioning in SQL, a powerful data management technique, involves dividing large tables into smaller, more manageable sections. This practice offers significant advantages, including improved query performance, enhanced scalability, and optimized storage utilization.
- Data Distribution: Partitions distribute data across multiple storage devices, improving query efficiency.
- Scalability: Partitions enable databases to handle growing data volumes without performance degradation.
- Query Optimization: Partitions allow databases to quickly locate and retrieve relevant data, reducing query response times.
- Storage Optimization: Partitions optimize storage space by segregating data based on specific criteria.
- Maintenance Simplification: Partitions simplify data maintenance tasks such as backups and data purging.
- Concurrency Control: Partitions enhance concurrency by allowing multiple users to access different partitions simultaneously.
- Data Security: Partitions can improve data security by isolating sensitive data in specific partitions.
In summary, partitioning by SQL plays a crucial role in managing large datasets efficiently. By leveraging the key aspects outlined above, organizations can harness the benefits of partitioning to optimize query performance, enhance scalability, and ensure data integrity.
Data Distribution
Data distribution is a fundamental aspect of partitioning in SQL. By distributing data across multiple storage devices, partitioning optimizes data access and query performance.
- Performance Optimization: Distributing data across multiple devices reduces the physical distance between the data and the processing unit, resulting in faster data retrieval and improved query response times.
- Load Balancing: Data distribution enables load balancing, where incoming queries are evenly distributed across the available storage devices, preventing bottlenecks and ensuring consistent performance.
- Data Locality: Partitions ensure data locality by storing related data on the same storage device. This improves query efficiency by reducing the need to access multiple devices for a single query, minimizing I/O operations and optimizing query execution.
- Scalability: Data distribution enhances scalability by allowing the addition of new storage devices without disrupting existing operations. This enables databases to handle growing data volumes without compromising performance.
In summary, data distribution is a key component of partitioning in SQL, contributing to improved query performance, enhanced scalability, and efficient data management.
Scalability
In the realm of data management, scalability is paramount to ensure that databases can seamlessly handle increasing data volumes without compromising performance. Partitioning in SQL plays a pivotal role in achieving scalability by segmenting data into smaller, more manageable partitions.
- Efficient Data Management: Partitions enable efficient data management by distributing data across multiple storage devices, reducing the burden on any single device and preventing performance bottlenecks. This distribution strategy ensures optimal performance even as data volumes grow.
- Optimized Query Execution: Partitions optimize query execution by allowing databases to focus on retrieving data from specific partitions that are relevant to the query. By eliminating the need to scan through the entire dataset, queries are executed faster, improving overall performance.
- Simplified Database Maintenance: Partitions simplify database maintenance tasks such as backups and data purging. By working with smaller, manageable partitions, maintenance operations can be performed more efficiently, reducing downtime and minimizing the impact on database performance.
- Enhanced Concurrency: Partitions enhance concurrency by allowing multiple users to simultaneously access and modify different partitions without interfering with each other's operations. This concurrency ensures that the database remains responsive even under high workloads.
In summary, the scalability benefits provided by partitioning in SQL are crucial for organizations managing large and rapidly growing datasets. By leveraging partitions, databases can maintain optimal performance, ensure efficient data management, and handle increasing data volumes without compromising the user experience.
Query Optimization
Query optimization is a crucial aspect of database management, directly impacting the performance and efficiency of data retrieval operations. Partitioning in SQL plays a pivotal role in query optimization by dividing large tables into smaller, more manageable partitions, which offers significant benefits:
- Reduced Scan Time: Partitions significantly reduce the amount of data that needs to be scanned during query execution. By isolating data based on specific criteria, the database can quickly identify and access only the relevant partitions, minimizing the I/O operations required to retrieve the necessary data.
- Targeted Data Retrieval: Partitions enable targeted data retrieval, allowing the database to focus its search efforts on specific partitions that are likely to contain the desired data. This targeted approach optimizes query execution by eliminating the need to examine irrelevant data, resulting in faster query response times.
- Improved Cache Efficiency: Partitions improve cache efficiency by reducing the amount of data that needs to be loaded into the cache. By working with smaller partitions, the database can effectively utilize the available cache memory, minimizing cache misses and improving overall query performance.
In summary, query optimization is a critical component of partitioning in SQL, enabling databases to quickly locate and retrieve relevant data. This optimization leads to reduced scan time, targeted data retrieval, and improved cache efficiency, ultimately resulting in faster query response times and enhanced database performance.
Storage Optimization
Storage optimization is a crucial aspect of database management, directly impacting the efficient utilization of storage resources. Partitioning in SQL plays a fundamental role in storage optimization by dividing large tables into smaller, more manageable partitions, offering significant benefits:
Efficient Storage Allocation: Partitions enable efficient storage allocation by segregating data based on specific criteria, such as date range, region, or product category. This segregation allows data to be organized and stored in a structured manner, minimizing wasted space and optimizing storage utilization.
Reduced Storage Costs: By optimizing storage space, partitioning can potentially reduce storage costs. By eliminating unnecessary data duplication and storing data in a more compact format, organizations can save on storage expenses, especially when dealing with large datasets.
Improved Data Management: Partitions simplify data management tasks such as data purging and archiving. By working with smaller, logical units of data, it becomes easier to identify and manage specific data subsets, ensuring efficient data retention and disposal practices.
In summary, storage optimization is a fundamental component of partitioning in SQL, enabling efficient storage allocation, reduced storage costs, and improved data management. By segregating data based on specific criteria, partitioning optimizes storage space utilization, minimizes data redundancy, and simplifies data management operations.
Maintenance Simplification
In the realm of database management, maintenance tasks such as backups and data purging are crucial for ensuring data integrity and optimizing storage utilization. Partitioning in SQL plays a pivotal role in simplifying these maintenance operations, offering significant benefits:
- Incremental Backups: Partitions enable incremental backups, where only the modified data within a specific partition needs to be backed up. This approach significantly reduces backup time and storage requirements, especially for large datasets where only a small portion of data changes frequently.
- Efficient Data Purging: Partitions simplify data purging by allowing administrators to target specific partitions for deletion. This targeted approach ensures that only the desired data is removed, minimizing the risk of accidental data loss and maintaining data integrity.
- Simplified Data Archiving: Partitions facilitate data archiving by enabling the easy identification and extraction of specific data subsets. By archiving less frequently accessed data into separate partitions, organizations can optimize storage costs and improve query performance on frequently accessed data.
In summary, maintenance simplification is a key advantage of partitioning in SQL. By enabling incremental backups, efficient data purging, and simplified data archiving, partitioning streamlines maintenance operations, reduces administrative overhead, and ensures data integrity, contributing to the overall efficiency and effectiveness of database management.
Concurrency Control
In the realm of database management, concurrency control is crucial for ensuring efficient and consistent data access in multi-user environments. Partitioning in SQL plays a vital role in enhancing concurrency, offering significant benefits:
- Concurrent Access: Partitions enable concurrent access to different partitions by multiple users or processes simultaneously. This means that multiple users can perform read and write operations on their respective partitions without interfering with each other's operations.
- Data Isolation: Partitions provide data isolation, ensuring that changes made by one user in their partition do not affect the data in other partitions. This isolation prevents data corruption and maintains data integrity, even in high-concurrency environments.
- Improved Scalability: Partitions enhance scalability by allowing multiple users to access the database concurrently, reducing the overall load on the system. This scalability is particularly beneficial for large databases with a high volume of concurrent transactions.
- Increased Throughput: By enabling concurrent access and reducing contention, partitions increase the overall throughput of the database. This increased throughput improves the performance of data-intensive applications and enhances the user experience.
In summary, the concurrency control benefits provided by partitioning in SQL are essential for managing high-concurrency database environments. By allowing multiple users to access different partitions simultaneously, partitioning ensures efficient and consistent data access, improves scalability, and increases throughput, contributing to the overall performance and effectiveness of the database system.
Data Security
In the realm of data management, security is paramount. Partitioning in SQL plays a crucial role in enhancing data security by providing the ability to isolate sensitive data in specific partitions. This isolation offers several advantages that contribute to the overall protection and integrity of sensitive information.
- Access Control: Partitions enable the implementation of fine-grained access controls, where specific users or groups can be granted access to specific partitions containing sensitive data. This granular control prevents unauthorized individuals from accessing confidential information, reducing the risk of data breaches and unauthorized data modifications.
- Data Segregation: Partitions facilitate data segregation by separating sensitive data from other data within the same database. This segregation minimizes the potential impact of a security breach, ensuring that even if one partition is compromised, the other partitions remain secure and unaffected.
- Audit and Compliance: Partitions simplify audit and compliance processes by providing a clear and structured organization of data. Auditors can easily identify and examine specific partitions containing sensitive data, ensuring compliance with regulatory requirements and industry standards.
- Data Masking and Anonymization: Partitions can be used in conjunction with data masking and anonymization techniques to protect sensitive data. By storing masked or anonymized data in separate partitions, organizations can reduce the risk of data exposure and misuse, while still maintaining the integrity of the original data for analytical purposes.
In conclusion, the data security benefits provided by partitioning in SQL are essential for organizations that handle sensitive data. By isolating sensitive data in specific partitions, partitioning enhances access control, facilitates data segregation, simplifies audit and compliance processes, and enables the implementation of data masking and anonymization techniques, contributing to the overall protection and integrity of sensitive information.
Frequently Asked Questions About Partitioning in SQL
Partitioning in SQL is a powerful technique for managing large datasets efficiently, improving query performance, and enhancing data security. Here are answers to some commonly asked questions about partitioning in SQL:
Question 1: What is partitioning in SQL?
Answer: Partitioning in SQL involves dividing a table into smaller, more manageable sections called partitions. Each partition contains a subset of the data in the table, based on specific criteria such as date range, region, or product category.
Question 2: Why should I use partitioning in SQL?
Answer: Partitioning offers several benefits, including improved query performance, enhanced scalability, optimized storage utilization, simplified maintenance, and increased concurrency.
Question 3: How do I create a partitioned table in SQL?
Answer: The syntax for creating a partitioned table in SQL varies depending on the database system. Generally, you will use a statement like CREATE TABLE table_name (column_list) PARTITION BY (partitioning_column), where partitioning_column specifies the column on which the table will be partitioned.
Question 4: What are the different types of partitioning in SQL?
Answer: There are two main types of partitioning in SQL: range partitioning and hash partitioning. Range partitioning divides the data into ranges based on the values in a specific column, while hash partitioning uses a hash function to distribute the data across partitions.
Question 5: How do I choose the right partitioning strategy?
Answer: The best partitioning strategy depends on the specific requirements of your data and application. Consider factors such as data distribution, query patterns, and performance goals when selecting a partitioning strategy.
Question 6: What are the limitations of partitioning in SQL?
Answer: While partitioning offers significant benefits, it also has some limitations. For instance, partitioning can increase the complexity of data management tasks such as inserts, updates, and deletes. Additionally, partitioning may not be suitable for all types of data or applications.
In summary, partitioning in SQL is a powerful technique that can significantly improve the performance, scalability, and management of large datasets. By understanding the concepts and benefits of partitioning, you can effectively leverage this technique to optimize your database design and improve the efficiency of your data management operations.
Conclusion
Partitioning in SQL has emerged as a fundamental technique for managing and optimizing large datasets. By dividing tables into smaller, more manageable partitions, partitioning offers a multitude of benefits that enhance database performance, scalability, and data management efficiency.
Throughout this exploration, we have delved into the concepts, advantages, and applications of partitioning in SQL. From improved query execution speeds and enhanced data distribution to simplified maintenance and increased concurrency, partitioning has proven its worth as a powerful tool for database administrators and data engineers.
As the volume and complexity of data continue to grow, partitioning will undoubtedly play an increasingly critical role in ensuring the efficient and effective management of large datasets. By embracing partitioning techniques, organizations can unlock the full potential of their data, derive valuable insights, and gain a competitive edge in today's data-driven landscape.
The Ultimate Guide To Understanding And Utilizing Kukaj.to
Who's The Lucky Lady? Kevin Whately's Marital Status Revealed
The Ultimate Guide To Welding Electrodes 6010: Applications And Uses

SQL PARTITION BY Clause When and How to Use It
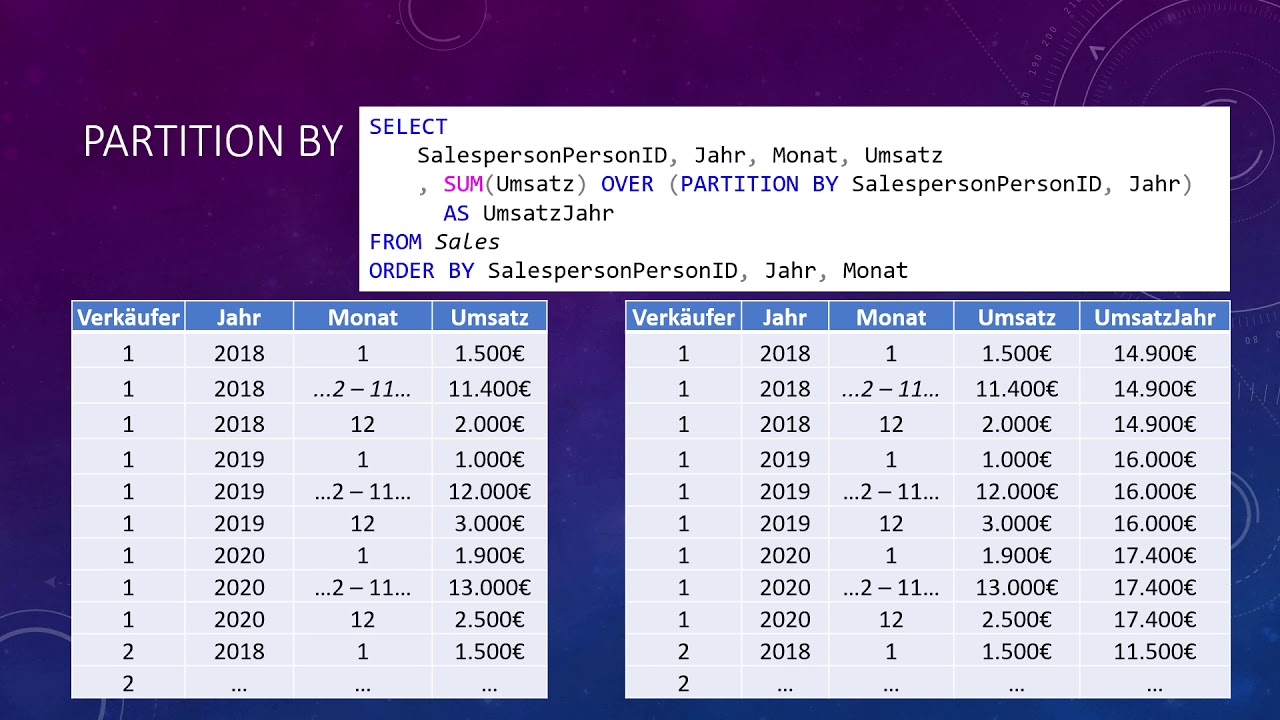
SQL PARTITION BY YouTube
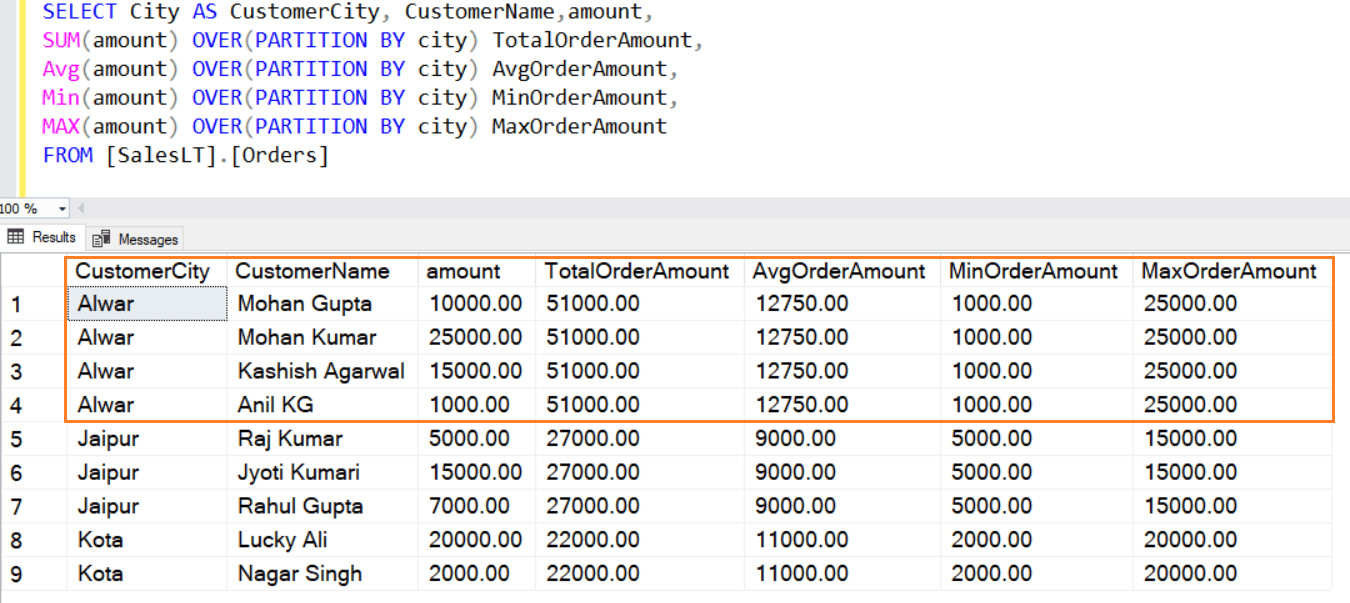
SQL PARTITION BY Clause When and How to Use It

